Gráfico de Afinidad a los diferentes segmentos
Es sabido que los marketers buscan constantemente tener un entendimiento más profundo sobre sus usuarios, para poder brindarles contenido que les sea relevante y así, obtener resultados satisfactorios en sus campañas o estrategias de marca.
Cuando un cliente quiere obtener esta clase de conocimiento desde la plataforma de Retargetly, suele encontrarla a través de segmentos que tenemos categorizados por intereses e intenciones de compra. Ya que ambos brindan amplia visibilidad acerca del comportamiento de los usuarios.
Lo que sucede, es que al intentar identificar cuales son los segmentos más relevantes para un cliente y poder accionar sobre estos, se podría pensar que son los que tienen mayor número de usuarios.
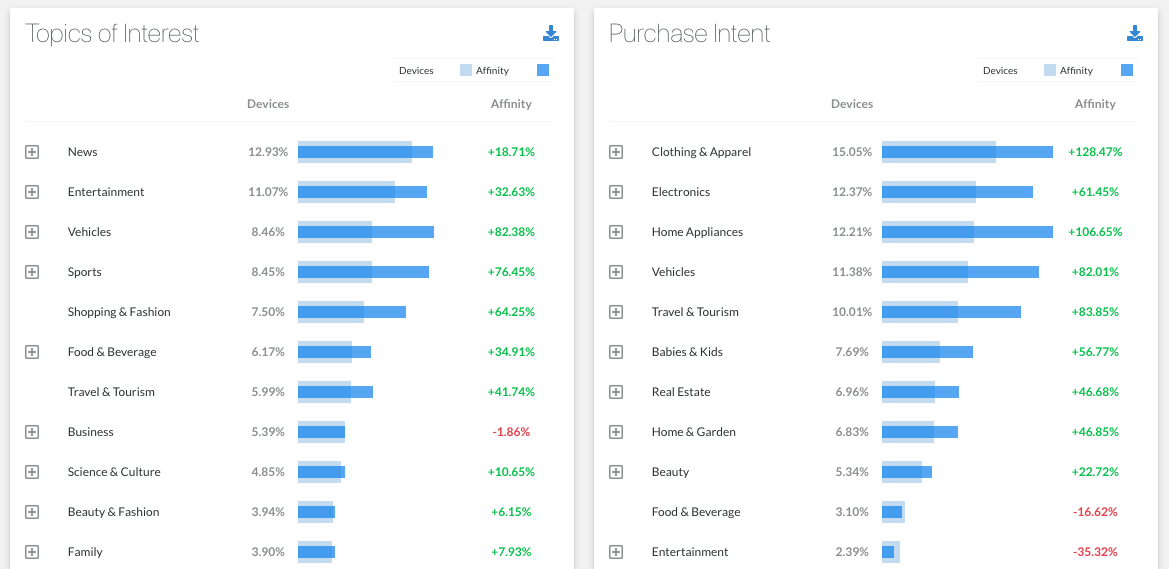
Pero existen segmentos que por lo general están altamente populados en nuestra red, como el de “interés en noticias”, que contiene un gran número de usuarios para la mayoría de nuestros clientes; sin que esto quiera decir que la gente enmarcada en este segmento esté realmente interesada en noticias, sino que al ser un segmento tan común y consultado en nuestra red, figura con muchos usuarios para la mayoría de cuentas.
Por otro lado, tenemos segmentos con intereses en tópicos poco usuales y que podrían ser de valor al elaborar una estrategia; pero de los que tenemos poca información, debido a que son menos consultados en todo nuestro tráfico.
La idea.
Ante esta problemática, quisimos poner foco en ver de qué manera podíamos brindar información valiosa dentro de estos segmentos y que resulte útil al momento de crear estrategias de marca.
Aquí es donde surge el Gráfico de Afinidad por Segmentos. Este reporte busca mostrar la afinidad que tiene la cantidad total de usuarios de un cliente, respecto al universo total de usuarios y poder utilizar esta información como punto de referencia para analizar sus comportamientos, y poder tomar desiciones de marca más inteligentes y más rentables.
Desarrollo del Backend
Tecnologías backend:
En lo que respecta al backend, el servicio que consume el frontend para generar el Gráfico de Afinidad con Segmentos está desarrollado en node js. Para la consulta de datos utilizamos mysql y elasticsearch; este último a través de un framework propio que desarrollamos con nuestro equipo de tecnología y que permite hacer consultas a elasticsearch con una sintaxis más amigable.
Cálculo de la Afinidad:
Para calcular la afinidad de cada segmento para un cliente determinado nos basamos en el algoritmo TF/IDF, el cual fue sugerido por nuestro equipo de Data Science, quienes lo utilizan en el día a día para la generación de distintos reportes.
Si bien el uso más frecuente para este algoritmo es en la minería de textos, se pudo adaptar con total éxito a nuestro caso de uso. La idea de este algoritmo, aplicado en este contexto, es saber lo siguiente:
- Qué tan afines o qué tan importantes son las personas que tienen algún interés o intención de compra, dentro de la red del cliente en comparación con nuestra base de datos.
- Identificar si las personas que pertenecen a estos segmentos tienen un peso considerable en la base de nuestros clientes en contraste de todo el tráfico que manejamos en nuestra red.
A lo largo del desarrollo de este feature probamos distintas maneras de calcular TF/IDF(existen varias fórmulas) y analizamos una por una para ver cual de todas nos daba un resultado de mayor precisión. Todo esto implicó realizar distintas combinaciones y cambios en las queries para dar con el mejor resultado, pero a final se logró el objetivo.
1era formula: TF (Term Frequency).
Optamos por realizar un cociente entre el porcentaje de personas que pertenecen a un segmento “x” en el cliente y el porcentaje de personas que pertenecen a este mismo segmento pero en el total de nuestra base.
Como resultado obtuvimos un porcentaje que representa qué tan mayor o qué tan menor es el porcentaje de gente correspondiente al segmento en cuestión, en relación a nuestra base de datos.
Esto podría representar fácilmente la afinidad pero tiene un gran problema, y es que no tiene en cuenta los segmentos más frecuentes o consultados y tampoco tiene en cuenta los segmento menos frecuentes o dicho de otra manera, de los que se posee menos información a la hora de medir el nivel de importancia.
Formula aplicada: (personas segmento x en el cliente/ total personas del cliente)
2da formula: TF*IDF (basado en el total de personas de nuestra base).
Nuestro equipo de Data Science nos brindó la variable que nos faltaba para poder solventar el inconveniente que tenía la 1era fórmula, el IDF (Inverse Document Frequency). El IDF sirve como suerte de compensador para poder castigar a aquellos segmentos más visitados y contrariamente ayudar a los de menor frecuencia.
Desde este punto, los resultados obtenidos fueron muy buenos. Pero faltaba ajustar la precisión de los resultados en relación a los segmentos más populares de nuestra base y reducir más el score para este tipo de segmentos.
Formula aplicada:(personas segmento x en el cliente/ total personas del cliente) * (total personas de nuestra base/ personas segmento x en nuestra base)
3ra formula: TF*IDF (IDF basado en el segmento con más personas de nuestra base).
En este último punto nos limitamos a jugar con una de las variables que se utilizan a la hora de calcular el IDF, a fin de aumentar la precisión en el cálculo.
En una primera aproximación habíamos utilizado la cantidad total de personas en nuestra base, como total en el cálculo del IDF. Pero esta vez decidimos utilizar como total de la base, el segmento con la mayor cantidad de personas de Retargetly. Gracias a este cambio, pudimos disminuir considerablemente el porcentaje de los segmentos más frecuentes.
Formula aplicada: (personas segmento x en el cliente/ total personas del cliente) * (max segmento de nuestra base/ personas segmento x en nuestra base)
Fuentes interesantes sobre el algoritmo de TF/IDF: https://www.quondos.com/seo-que-es-tfidf-y-como-puede-ayudarte/https://en.ryte.com/wiki/TF*IDF
Desarrollo de caché para la obtención de datos:
Uno de los principales problemas al momento de obtener los datos para la generación del reporte, fue el tiempo que se tardaba en realizar ciertas queries de elasticsearch, por lo tanto que optamos por el desarrollo de una caché para guardar el resultado de las queries que más tiempo tardaban en resolverse y de esta manera poder reducir el tiempo de respuesta del endpoint.
Para esto, desarrollamos un servicio que corre cada 24 horas y se encarga de consultar las queries que más tiempo y procesamiento consumen de elasticsearch. Los resultados de estas queries los guardamos en tablas de mysql para que posteriormente sean consumidos por nuestro endpoint para el cálculo de la afinidad.
El resultado fue exitoso, ya que logramos reducir considerablemente los tiempos de respuesta de nuestro endpoint, de 15–20 segundos a 3–5 segundos.
Arquitectura final del backend:
Desarrollo del Frontend
La solución en Frontend está desarrollada con AngularJS en su versión 1.7 con orientación a componentes, el layout está armado con CSS y HTML puro usando CSS-GRID nativo.
¿Por qué HTML y CSS Puro?
Si bien existen alternativas y librerías gráficas disponibles para crearCharts(Chart.JS), en nuestra investigación previa pocas se adaptan al nivel de customización que requería el feature; exceptuando D3, pero la curva de aprendizaje es un poco alta para nuestro deadline además de ser un overkill para algo que resulta más sencillo y mantenible con un custom approach.
¿En qué nos inspiramos para el gráfico a mostrar?
Nuestro equipo de Data Science cuenta con la capacidad de generar estos gráficos en un exportable HTML desde Python usando la librería Seaborn;pero está limitado solo a los segmentos elegidos para un reporte, no hay mayor capacidad de interacción o expansión de segmentos padres y visualizar sus hijos en el mismo gráfico, y esto es lo que requerían nuestros clientes.
Tomando como inspiración este reporte y aplicando un diseño atómico, creamos nuestro CodePen Base para los componentes que constituyen la solución.
¿Cómo lo hicimos?
Para componentizar una solución desde el Frontend, necesitábamos lo siguiente:
- Un componente que nos permita obtener la data a procesar y renderizar el layout base que contiene al gráfico.
- Un componente que sea el gráfico, procese y genere los promedios; además de los máximos y mínimos necesarios para crear el gráfico de afinidad.
- Cada barra de afinidad debe ser un componente que reciba cada dato de manera individual, establezca el formato de presentación, muestre si tiene hijos o no y en función de esto pueda expandirse en un nuevo gráfico de afinidad para mostrar sus hijos.
Para tener una visión más clara de nuestra solución, consideremos el siguiente diagrama donde podemos ver las interacciones entre cada uno de los componentes:
Son tres los componentes que constituyen la solución del reporte de afinidad:
- <Affinity Container Component>
- <Affinity Graphic Component>
- <Affinity Graphic Item Component>
1. Affinity Container Component
Se comunica con la api para que en función de la selección de un segmento o toda la red por defecto, se obtenga la data necesaria para generar el gráfico de afinidad. Envía la data recibida al componente <Affinity Graphic Component>.
2. Affinity Graphic Component
Recibe y procesa la data recibida por <Affinity Container Component>, contiene toda la lógica que en función de la configuración propia, calcula promedios y máximos y mínimos necesarios para renderizar cada ítem del gráfico de afinidad. Es en este componente donde se integra el GRID-Layout que forma la estructura del gráfico. Dentro de su estructura renderiza iterativamente cada ítem del grafico como un componente <Affinity Graphic Item Component>.
3. Affinity Graphic Item Component
Recibe la data de <Affinity Graphic Component>, su función principal es darle formato entendible a cada dato que compone al gráfico; además de tener la posibilidad de renderizar en su layout un nuevo gráfico de afinidad con todos sus hijos. Esto le agrega al componente la capacidad de ser recursivo.
El desarrollo del Gráfico de Afinidad con Segmentos, fue una triple colaboración entre Frontend, Backend y Data Science. Construir este tipo de soluciones implica mucho esfuerzo de ingeniería de distintas áreas y nosotros seguimos apostando a este tipo de mini-squads para generar soluciones robustas para nuestros clientes.
Esta funcionalidad fue creada por: Juan Luis Marval (Frontend), Salvador Ríos (Backend) y Francisco Rangel (Backend).
Brindaron soporte desde Data Science: Julian Ferreiro y Martin Caravario.